Scheduling and job duration¶
GPULab offers many scheduling option that you can control in your job request.
💨 If you want to do the absolute minimum for now, read the Quick Migration Guide.
🚀 If you want your jobs to start sooner, the Scheduling Tutorial is a good start.
🧑🎓 To learn how to use the scheduling options optimally, more in depth explanations can be found in the Explanation section.
📃 The Examples section has basic examples to get you started quickly.
📖 The Reference section contains all the details you can wish for.
Basics¶
💨 Quick Migration Guide¶
You don’t need to do anything new, if this is OK:
- GPULab always stops your jobs after 2 weeks
- GPULab very seldomly stop your jobs after at least 1 week
If that is not OK, add this to your job:
"request": {
"scheduling": {
"minDuration": "2 weeks",
"maxDuration": "2 weeks"
}
}
Where you replace “2 weeks” by the required maximum duration of your job.
This will work, but you can cause your jobs to possibly run earlier, by using the scheduling options in a smarter way. To learn more, read up on the scheduling in the scheduling tutorial.
⚠️Note⚠️: These defaults might change in the future. For this reason, it is useful to always set a sane minDuration and maxDuration for each of your jobs. Be aware that setting these higher than strictly needed can be a disadvantage: GPULab will take these values into account both to check if starting the job is possible, and to determine which QUEUED job gets priority to start.
🚀 Scheduling Tutorial¶
For each job you run, choose how long you think it will run maximally. Is 24 hour certainly enough? Or 1 week?
Make a choice, and use this for maxDuration.
Now consider this scenario: A lot of people are using GPULab, and a lot of jobs stay QUEUED because all GPULab is fully in use.
Your own job has been running for a while now. Is it OK if GPULab halts your job to allow other people’s job to run?
Decide how long you want your job to run, before GPULab may stop it to make room for other jobs, and set this as minDuration.
Off course, don’t set minDuration larget than maxDuration (that doesn’t make sense). But you can set them equal.
Your GPULab job request will now look like this:
"request": {
"scheduling": {
"minDuration": "2 weeks",
"maxDuration": "2 weeks"
}
}
You probably want to make sure that your job is not QUEUED long, and starts quickly.
There are some ways you can improve how fast your job starts:
- Don’t waste resources: GPULab will prefer to start jobs of people that have used GPULab the least lately. So always make sure your jobs do not use more CPU, GPU and memory than they need, and that they don’t run longer than needed. This will make your future jobs run sooner.
- Set
minDurationandmaxDurationas low as you can. This will allow GPULab to start the jobs sooner:- One case happens when there are future reservations. GPULab will not start long jobs if they would still run when a reservation begins.
- A second case involves private clusters. If you specify a low
minDurationand noclusterIdin your job request, GPULab might start your job on a private cluster. The owners of the hardware of these clusters have absolute priority on them, but when they are not using the cluster, other jobs can use it as “guests”. If the owners of a private cluster start a job on their cluster, that job will cause “guest jobs” that have reached theirminDurationto stop. - In the future, the scheduler might also give priority to short jobs in certain conditions.
When GPULab halts your job, you’ll need to continue the work by manually queueing a new job. You can however make your job “restartable”, which will cause GPULab to queue a new job for you automatically. See Restartable Job for more info.
🧑🎓 Explanation¶
Major new concept: HALT¶
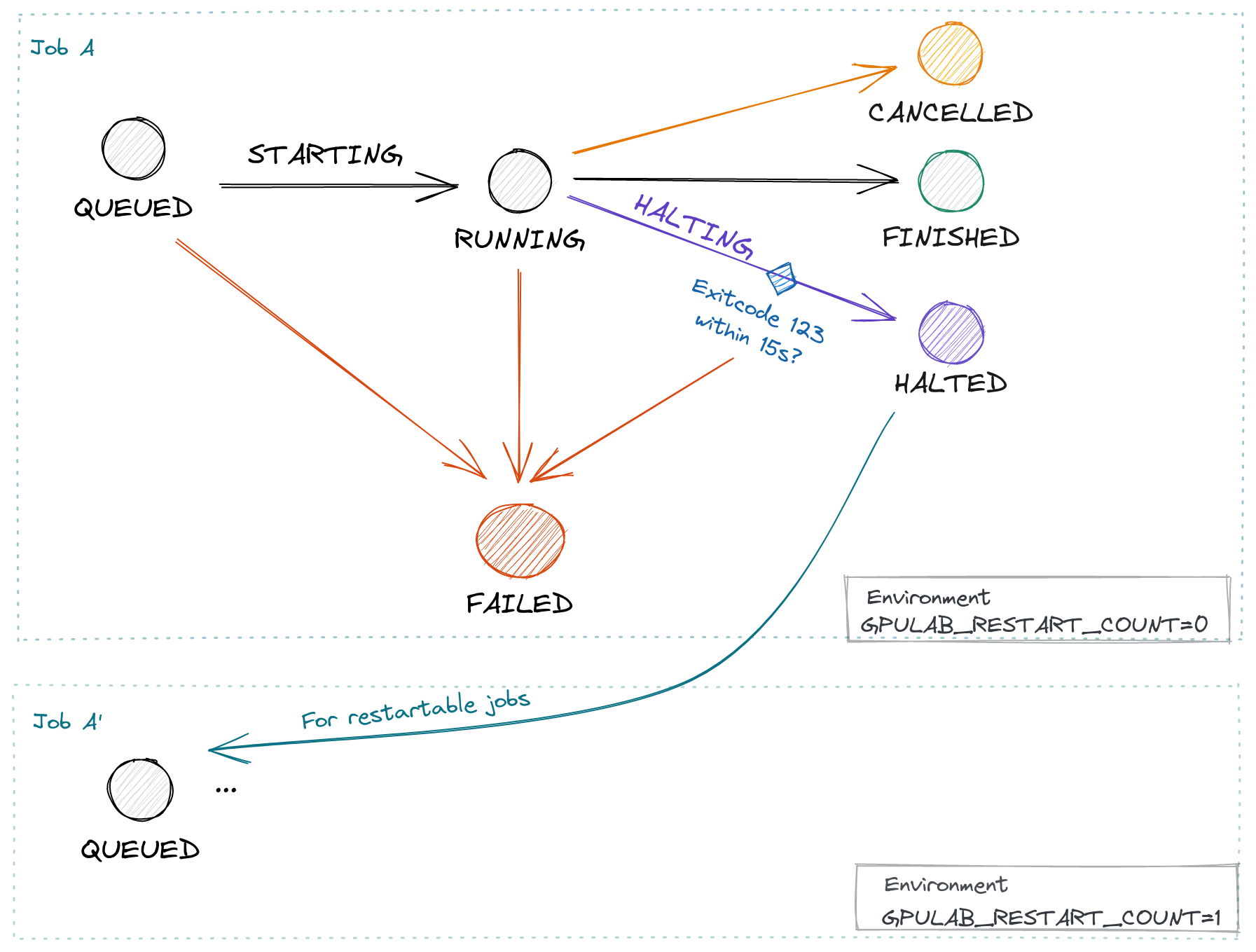
GPULab uses different words and states when “stopping” a job:
Stop requested by user (or admin): Cancel a job, corresponding state: CANCELLED
GPULab stops jobs that exceed maxDuration: Cancel a job, corresponding state: CANCELLED
Something goes wrong: A job Fails, corresponding state FAILED
Job itself stops (because job command returns): The job Finished, corresponding state: FINISHED
GPULab scheduler stops jobs to garuantee fairness: halt a job, corresponding states: MUSTHALT, HALTING and HALTED
- “Halting” a job is not simply stopping it. It is a procedure that gives the job time to gracefully stop, see “GPULab HALT procedure” for details.
- The GPULab scheduler only stops to garuantee fairness, and only if other jobs will take their place immediately.
- Users can also manually trigger job halt, to test their jobs.
Major new concepts: minDuration and maxDuration¶
GPULab scheduling has 2 major concepts that can be confusing, but are very important to understand: minDuration and maxDuration.
The concepts are explained in full detail in the next section, but due to their importance, here’s the most important thing to know:
GPULab scheduling will assume your job runs for a duration between minDuration and maxDuration. You choose both of these values yourself (but there are defaults: 1 week and 2 weeks respectively).
Important facts:
- GPULab scheduling promises to never automatically stop your job before minDuration.
- It is always OK if your job stops itself, or you stop your job manually, before minDuration is reached. (Due to a failure, completing the work, etc.)
- GPULab crashes and hardware issues can stop your job at any time, even before minDuration. We can make no guarantees here, but off course we do everything to keep this to a minimum.
- GPULab will cancel your job to force it to respect maxDuration.
- Between minDuration and maxDuration, GPULab scheduling may decide to halt your job. This certainly does not happen for every job! This is an automatic decision by the GPULab scheduler, with the aim to let other users have a fair share, to give priority to interactive jobs (juypterhub), to make room for reservations, etc. The GPULab scheduler tries to avoid doing this, which means that during low overall GPULab usage, it will almost never happen. During high overall GPULab usage, it is more likely to occur.
- Setting minDuration (and maxDuration) to low values voluntarily, will increase the changes your job gets started. Setting minDuration and maxDuration to high values, might cause your job to be QUEUED for longer.

How to influence how fast a job starts¶
The scheduler allows GPULab to:
- Schedule preemptible jobs on clusters which are normally inaccessible for them (“private” clusters).
- Guarantee resource reservations (for classroom exercises, thesis deadline, …) while still allowing to efficiently schedule jobs around it.
- Take fairness into account when starting jobs. The more resources you’ve recently used, the more chance your job will not start, or will be halted while running.
This means that you can influence how fast your job starts, with these methods:
- Avoid wasting resources. Use just what you need, and make sure you use them at all time, and do not let them “idle”.
- Setting
maxDurationto a low value voluntarily - Setting
minDurationto a low, or zero, value voluntarily - Setting
restartableto true (+ supporting the halt procedure correctly)
GPULab HALT procedure¶

When the GPULab scheduler halts a job, it will not simply force stop it. A procedure is started that gives the job time to gracefully stop.
This procedure is optional for jobs that do not care about a graceful stop. They will simply be stopped after a short delay.
Restartable jobs however, need to correctly halt, or they will not be restarted. (Unless allowHaltWithoutSignal is set to true)
The procedure to “halt” a job is:
- GPULab will send a SIGUSR1 signal to the job.
- The job then needs to stop with exit status 123 within 15 seconds.
- The job is stopped after these 15 seconds, it it does not stop by itself.
If the job does not stop on time, or stops with another exit code, the job is set to the FAILED state. If the job does correctly stop, GPULab will set the job to the HALTED state.
Restartable Jobs¶
You can specify that your job is restartable using request.scheduling.restartable.
When a restartable job is halted by the scheduler, and the halt procedure was succesfull (state HALTED), or allowHaltWithoutSignal is true, a new job will be created based on the original job. Most job details will be identical, but maxDuration will be reduced by the time your job ran.
The new job will be in the QUEUED state, which means it will automtically be started later to continue the work of the job. See the Restartable Job reference for details and the Restartable Job example.
📃 Examples¶
Advanced Scheduling Job¶
{
"name": "Scheduling Example",
"description": "Example Job with all scheduling options",
"request": {
"docker": {
"command": "/project/start_job.sh",
"image": "debian:stable",
"storage": [ { "hostPath": "/project_ghent", "containerPath": "/project" } ]
},
"resources": {
"cpus": 2,
"gpus": 1,
"cpuMemoryGb": 2,
},
"scheduling": {
"interactive": true,
"restartable": false,
"allowHaltWithoutSignal": false,
"maxDuration": "1 week",
"notBefore": "2020-01-01T00:00:00+01:00",
"notAfter": "2030-01-01T00:00:00+01:00",
"minDuration": "1 hour",
"maxSimultaneousJobs": {
"bucketName": "aBucketName",
"bucketMax": 1
}
"reservationIds": ["f6dbca7b-58fd-47e3-9ac4-9ad33e7f6030"],
}
}
}
Restartable Job¶
Example Job:
{
"name": "RestartDemo",
"description": "Demo of Restartable Job",
"request": {
"docker": {
"command": "/project/start_job.sh",
"image": "debian:stable",
"storage": [ { "hostPath": "/project_ghent", "containerPath": "/project" } ]
},
"resources": {
"cpus": 2,
"gpus": 1,
"cpuMemoryGb": 2,
},
"scheduling": {
"restartable": true,
"allowHaltWithoutSignal": false,
"maxDuration": "1 week",
"minDuration": "1 hour",
"interactive": false
}
}
}
Example content of /project_ghent/start_job.sh:
#!/bin/bash
halt_handler() {
echo "saw SIGUSR1 @ $(date)"
# TODO: if needed, make the job save its work and stop
exit 123
}
trap halt_handler SIGUSR1;
echo "Job started at $(date)"
echo "GPULAB_JOB_ID=${GPULAB_JOB_ID}" # different for each restart
echo "GPULAB_RESTART_INITIAL_JOB_ID=${GPULAB_RESTART_INITIAL_JOB_ID}" # always the same, for original and restarts
echo "GPULAB_RESTART_COUNT=${GPULAB_RESTART_COUNT}"
if [ $GPULAB_RESTART_COUNT -lt 1 ]
then
# TODO: code to start your job the first time
else
# TODO: restart_my_job
fi
📖 Reference¶
GPULab Scheduling Options Overview¶
When you specify no GPULab scheduling options, GPULab assumes:
- You don’t care how long it takes before your job starts
- When GPULab halts your job, it may never restart your job automatically.
- Once it starts, GPULab itself will not halt your job in less than 1 week.
- You job should not run longer than 2 weeks
You can specify the following options in request.scheduling (click the links to get more info):
{
"interactive": true,
"restartable": true,
"maxDuration": "1 week",
"notBefore": "2020-01-01T00:00:00+01:00",
"notAfter": "2030-01-01T00:00:00+01:00",
"minDuration": "1 hour",
"maxSimultaneousJobs": {
"bucketName": "aBucketName",
"bucketMax": 1
}
"reservationIds": ["f6dbca7b-58fd-47e3-9ac4-9ad33e7f6030"],
}
The defaults are:
{
"interactive": false,
"restartable": false,
"allowHaltWithoutSignal": false,
"maxDuration": "2 weeks",
"minDuration": "1 week",
"notBefore": null,
"notAfter": null,
"maxSimultaneousJobs": null
"reservationIds": null,
}
Interactive jobs¶
| Option: | interactive |
| Value: | boolean: true or false |
| Default: | false |
Interactive jobs will either run immediately, or become FAILED. They will never be QUEUED for a long time.
Make your job interactive if you want it to start right away. You typically do this for jobs that you need to directly interact with.
Jupyterhub automatically sets this flag when creating jobs.
Not After and Not Before¶
| Option: | notAfter and notBefore |
| Value: | a date, in RFC3339 format |
| Default: | none |
The notBefore option request GPULab not to start the job before a specified date. It will stay QUEUED at least until the requested time.
The notAfter option request GPULab to FAIL the job if it is still QUEUED at a specified date. This does not affect a job that is already running job at the notAfter date, it only prevents QUEUED jobs from starting after the date.
Maximum Duration¶
| Option: | maxDuration |
| Value: | string: number + time unit |
| Default: | “2 weeks” |
The maximum duration of this job. GPULab will always cancel your job if it is RUNNING for this period of time. It will then be in the state CANCELLED.
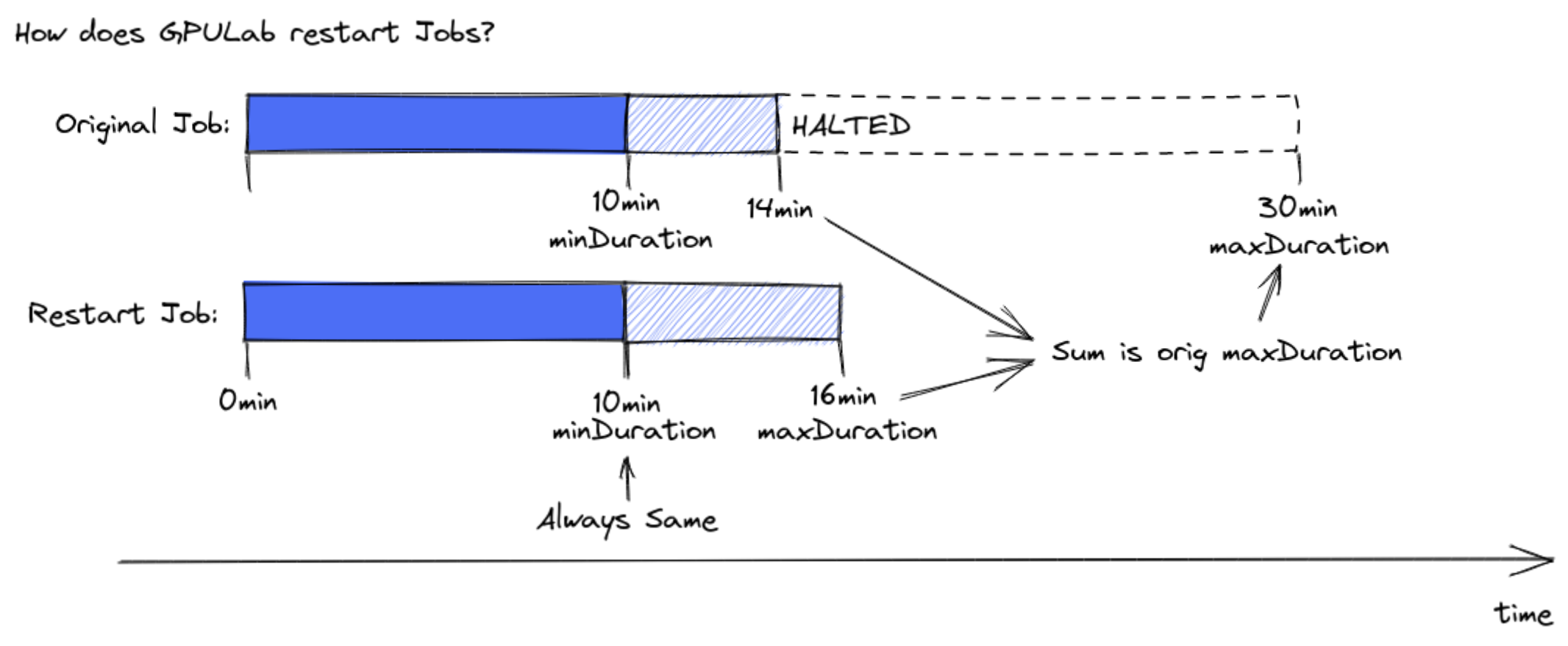
If the job has been restarted (once or more), the total duration of all the job runs is used.
Example: If a restartable job specifies “8 hour” as maxDuration, and it is halted after running 1 hour, the restarted job will have a maxDuration of “7 hours”.
The format is a string, containing a number followed by a time unit (both plurar and singular units are allowed). Examples: 5 minutes, 3 hour, 3 hours, 2 days, 1 week, …
Minimum Duration¶
| Option: | minDuration |
| Value: | string: number + time unit |
| Default: | “1 week” |
GPULab might halt this job after this duration. It will not automatically halt the job before this duration is reached.
Note that there is a default of “1 week”. You can reduce or extend this:
- Lowering
minDurationallows GPULab to schedule this job earlier than it would otherwise, but there is a chance your job will be stopped after this time. (If it is restartable, it will however restart later.) Additionally, jobs with very lowminDurationmight be scheduled on private clusters, where your job would otherwise never run. These jobs will automatically be halted as soon as possible when the owners of the private cluster run jobs on it (since they get full priority for these clusters). - Increasing
minDurationwill prevent GPULab from halting it, but jobs with a highminDurationmight stay QUEUED longer then jobs with lowminDuration.
Tip: If your job can be halted, set minDuration to the minimum time your job needs to do useful work. For example, If your job needs 10 minutes to prepare the dataset before starting to do work, and your job typically saves results each 10 minutes, set this to at least 30 minutes.
If it makes no sense to ever stop your job, set this as high as maxDuration, so that your job has time to complete without GPULab ever halting it.
The format is a string, containing a number followed by a time unit (both plurar and singular units are allowed). Examples: 5 minutes, 3 hour, 3 hours, 2 days, 1 week, …
When GPULab halts a job that has reached it’s minimum duration, it will send SIGUSR1 to the job command. The job need to react to SIGUSR1 by exiting with exit status 123 within 15 seconds. It will then be set to the HALTED state. If the job does not stop on time, or stops with another exit code, the job is stopped and set to the FAILED state. See also the GPULab HALT procedure.
Restartable Jobs¶
| Option: | restartable |
| Value: | boolean: true or false |
| Default: | false |
A restartable jobs can not only be automatically halted by GPULab (see minDuration), it can also later be automatically restarted by GPULab. This means that GPULab is able to “pause” your job during busy periods, and restart it when things calm down.
Be sure to set minDuration correctly for restartable jobs.
The GPULab scheduler might start restartable jobs sooner than it would start non-restartable jobs.
Important: To make a job restartable, you need to do more than just set this flag. You also need to change the behaviour of your job. Restartable jobs need to react to SIGUSR1 by exiting with exit status 123 within 15 seconds. IT will then be set to HALTED and will restart. If the job does not stop on time, or stops with another exit code, the job is set to the FAILED state and does not restart. See also the GPULab HALT procedure.
Not that if a job does not halt correctly, GPULab will not try to restart it. If a job does halt correctly, GPULab will immediately create a new “restart job” based on it, and set the state of this new job to QUEUED.
A job can detect if it has been restarted, by looking at the GPULAB_RESTART_COUNT environment variable.
Each restart has a new job UUID, but contains the UUID of the original job in the GPULAB_RESTART_INITIAL_JOB_ID environment variable (which is also present in the original job).
Allow HALT without signal¶
| Option: | allowHaltWithoutSignal |
| Value: | boolean: true or false |
| Default: | false |
Some haltable jobs do not require any work to be done for the job to halt. They are robust enough to be stopped without warning at any moment. An example are jobs that implement checkpointing at frequent intervals.
In such cases, the job should have allowHaltWithoutSignal set to true. GPULab will then skip the halt procedure, stop the job immediately and set it to the HALTED state.
If the job is restartable, it can then off course be restarted immediately.
Maximum Simultanious Jobs¶
| Option: | maxSimultaneousJobs |
| Value: | an object with 2 keys |
| Default: | none |
Control how many of your jobs can run at the same time. Note that GPULab also limits the number of jobs per user and/or cluster. This feature cannot be used to go over that limit. This is only used to voluntary reduce your simultaneous job limit. To increase the simultaneous job limit, contact GPULab support.
How it works: Invent a “Bucket Name” that nobody else will accidentally use. Give all grouped jobs this same “Bucket Name”. “Bucket Max” determines the maximum number of jobs in that group.
Different users can share the same bucket by simply using the same name. “Bucket Max” must be set to the same value for all jobs with the same “Bucket Name”, or unpredictable behaviour will result.
Tip: This option is useful if you want to do a big parameter sweep, that takes many jobs. You can voluntary limit this sweep to only a few jobs (or even 1), in order not to use too many GPULab resources at the same time.
Example object:
{
"bucketName": "my parameter sweep limit",
"bucketMax": 2
}
reservationIds¶
| Option: | reservationIds |
| Value: | a list of UUIDs |
| Default: | none |
GPULab admins can create reservations. These reservations block access to entire clusters, or parts of them, during a specified time.
If you request a reservation, the GPULab admins will give you a reservation UUID. You need to add this ID to your jobs, in order for them to be allowed to run during the reservation timeframe.
Note that it is best to add this reservation UUID to jobs that you start before the reservation as well, as GPULab will stop jobs not belonging to the reservation when the reservation starts.
You can add multiple reservation IDs, but typically only 1 reservation is involved.

